机器学习系列(三)——误差(error),偏差(bias),方差(variance)
训练机器学习模型时,我们希望得到一个泛化性能优异的模型。在上一篇博客回归模型中,当我们采用多项式回归,并不断增加多项式的次数时,模型越来越复杂,但是在测试集上的误差并没有逐步降低。

这表明一个复杂的模型并不总是能在测试集上表现出更好的性能,那么误差来自哪里呢?
泛化误差(error)
我们知道,算法在不同训练集上学得的结果很可能不同,即便这些训练集是来自于同一个分布。以回归任务为例,对测试样本x,令yD为x在数据集上的标记,y为x的真实标记,由于噪声的存在,有可能yD≠y,f(x;D)为在训练集D上学得函数f对x的预测输出。因此,算法的期望预测(在不同训练集上学得的模型对样本x的结果的预测值的均值)可以表示为
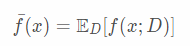
不同训练集学得的函数f的预测输出的方差(variance)为
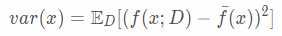
期望输出与真实标记之间的差距称为偏差(bias),即
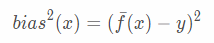
噪声为
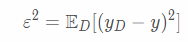
为方便讨论,假定噪声期望为零,即ED[yD−y]=0。算法的期望泛化误差(也采用平方误差度量)为
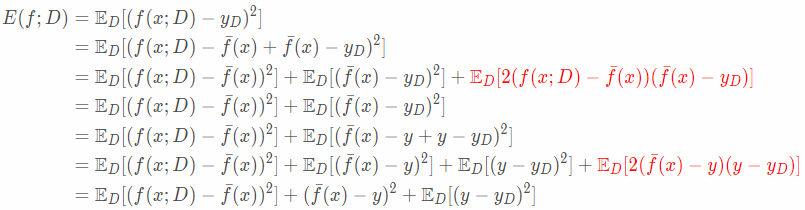
式中,第一个加红公式等于0,因为fˉ(x)−yD是一个标量,而根据期望预测公式fˉ(x)=ED[f(x;D)],我们可以得到ED[(f(x;D)−f¯(x))]=0,所以整个加红式子的值为0。同理第二个加红公式等于0,因为噪声期望为0。于是
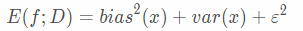
也就是说,泛化误差可分解为偏差、方差与噪声之和。噪声无法人为控制,所以通常我们认为
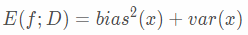
现在知道了泛化误差来自哪,就需要进行针对性控制。
偏差(bias)与方差(variance)
根据上面的定义,偏差(bias)反映了模型在样本上的期望输出与真实标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。方差(variance)反映了模型在不同训练数据集下学得的函数的输出与期望输出之间的误差,即模型的稳定性,反应的是模型的波动情况。下面用打靶的例子直观展示了偏差和方差。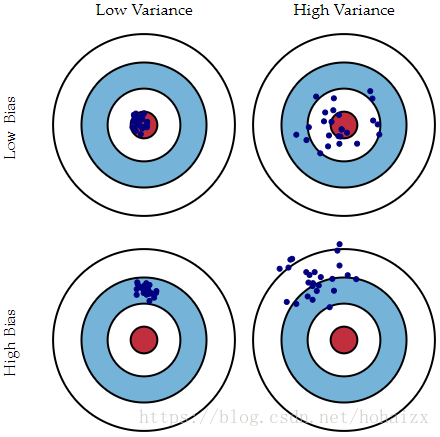
图中红色的靶心表示测试样本的真实标记,蓝色的点表示模型在不同训练集上选出的函数的输出。第一列的两个图中,蓝色的点都比较集中,说明模型的稳定性好,也就是方差小;第一行的两个图中,蓝色点的中心都比较靠近红色靶心,说明模型的拟合能力强,也就是偏差小。所以总结如下:
low bias and low variance:又准又稳
low bias and high variance: 准但不稳
high bias and low variance:不准但稳
high bias and high variance:不准又不稳
那模型和偏差、方差之间的对应关系是什么样呢?还是以回归任务为例,看一个极端例子,y=c ,不论模型的训练数据如何变化,学得的函数都不会变,因此f(x;D)的输出都相同,即模型的稳定性非常好,但是对训练集的拟合也不是很好,显然对于测试样本的预测也不会很准确,这种对训练集刻画不足的情况,称为欠拟合(underfitting)。逐渐增加模型的复杂度,学得的函数对训练数据的拟合越来越好
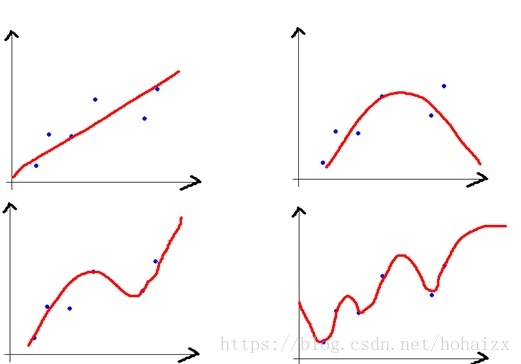
但是,对于一个复杂的模型,当我们稍微改变训练样本时,学得的函数差距将非常的大
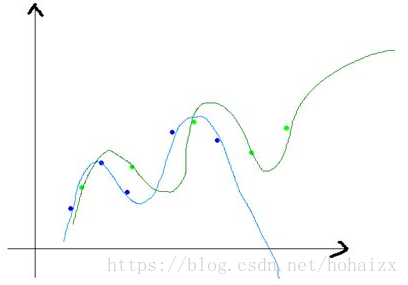
这说明复杂的模型对训练样本拟合很好,但是模型的波动性也很大,很可能在测试样本的表现非常差。可以理解为,复杂的模型将训练样本的特性当作全体样本的通性,将噪声引入了模型中,这种现象称之为过拟合(overfitting)。所以我们需要在模型复杂度之间权衡,使偏差和方差得以均衡(trade-off),这样模型的整体误差才会最小。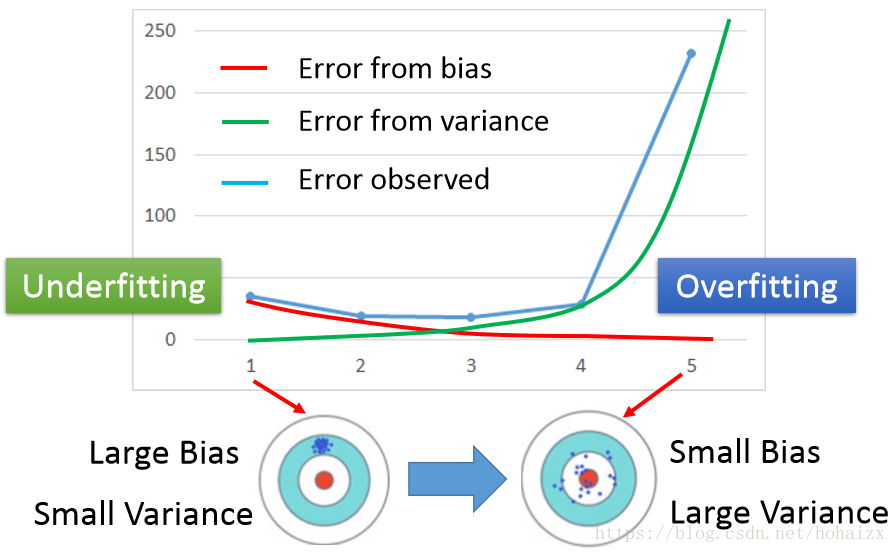
欠拟合和过拟合应对策略
欠拟合(刻画不够)
- 寻找更好的特征,提升对数据的刻画能力
- 增加特征数量
- 重新选择更加复杂的模型
过拟合(刻画太细,泛化太差)
- 增加训练样本数量,样本多了,噪声比中就减少了
- 减少特征维数,高维空间密度小
- 加入正则化项,使得模型更加平滑
模型选择
同一模型在不同训练集上学得的函数往往不同,那我们怎样才能选出最好的模型和最好的函数呢?可以采用交叉验证(Cross Validation)法,其基本思路如下:将训练集划分为K份,每次采用其中K-1份作为训练集,另外一份作为验证集,在训练集上学得函数后,然后在验证集上计算误差。再次选择另外K-1份数据再次重复上述过程,最终模型的误差为学得的K个函数的误差的平均值,并依据此值选择最佳模型,最后在整个训练集上训练选择的最佳模型,并在测试集上进行测试。
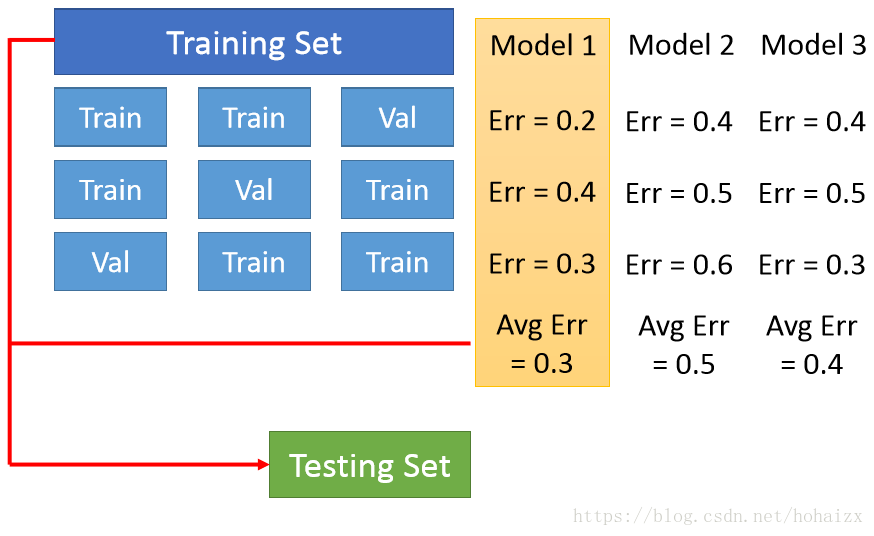
同时,交叉验证也解决了上面说的variance(不同训练集学得的函数的差异)和bias(不同函数的平均值)两大问题。说白了,交叉验证验证了你的模型是否够精确,够稳定,不能说在某个数据集上表现好就可以,你做的模型是要放在整个数据集上来看的,毕竟泛化能力才是机器学习的核心。