padding
当进行卷积操作时,例如一个3x3的过滤器卷积一个6x6的图像,不断地卷积过后,图像就会变得越来越小。并且边缘的像素卷积比中间的采用少,会造成边缘的信息丢失或者更准确来说角落或图像边缘的信息发挥的作用较小。因此需要运用padding进行填充。
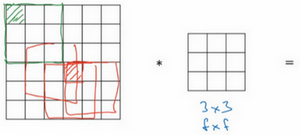
如上图:这个像素点(绿色阴影标记)只被一个过滤器输出所触碰或者使用,因为它位于这个3×3的区域的一角。但如果是在中间的像素点,比如这个(红色方框标记),就会有许多3×3的区域与之重叠。所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。
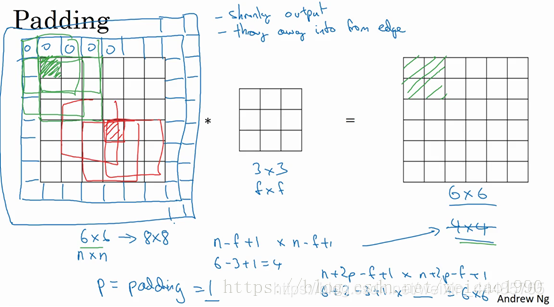
因此,如果我们在卷积操作之前填充这幅图像。在图像边缘再填充一层像素,这个6x6的矩阵就会变为8x8,再进行3x3的卷积,得出后的图像就依然是6x6。
同时,padding还有两种形式,分别是SAME和Valid.
SAME
用SAME填充过后,输入大小如6x6则输出结果仍为6x6。
| 1 |2 | 3 |0|
|–|–|–|–|
| 5 | 6 |7|0|
如上表,如步长为2,向右滑动两格。会发现剩下的不满足2x2,SAME方法便会填充增加第4列,通常为0。
Valid
Valid卷积意味着不填充,这样的话,如果你有一个nn的图像,用一个ff的过滤器卷积,它将会给你一个(n-f+1)*(n-f+1)维的输出。这类似于我们在前面的视频中展示的例子,有一个6×6的图像,通过一个3×3的过滤器,得到一个4×4的输出。
LeNet-5
LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。出自论文Gradient-Based Learning Applied to Document Recognition。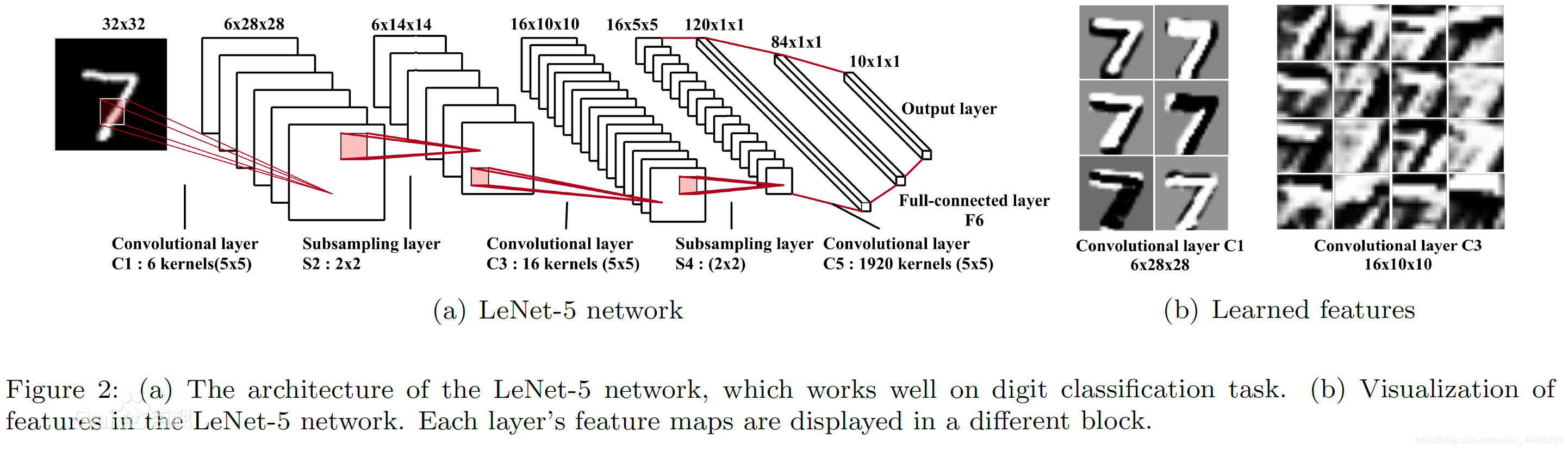
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征。
- input层,输入一个32x32的图像。在卷积时没有使用padding(文章中有提到32x32的输入实际上比常用的28x28的输入要大,可以认为是在输入的时候就已经padding过了)。
- C1,C3,C5三层均为卷积层,卷积核均为5x5.
- S2,S4均为池化层,采样区域均为2x2.
- F6为全连接层,计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
- Output层也为全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
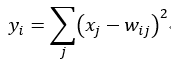
上式的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
| 0 | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 0 | 7 |
| 8 | |
| 9 |