这一篇博客将介绍机器学习中另一个重要的任务——分类(classification),即找一个函数判断输入数据所属的类别,可以是二类别问题(是/不是),也可以是多类别问题(在多个类别中判断输入数据具体属于哪一个类别)。与回归问题(regression)相比,分类问题的输出不再是连续值,而是离散值,用来指定其属于哪个类别。分类问题在现实中应用非常广泛,比如垃圾邮件识别,手写数字识别,人脸识别,语音识别等。
思考
首先思考一个问题,能不能用回归问题的解法去求解分类问题呢?
以二分类问题为例,对于类别1,我们假设其目标值为1,对于类别2,假设其目标值为-1。在回归问题中,我们需要找到一个函数,使得函数的预测值尽可能的接近目标值。如下图所示,为了方便可视化,假设每个样本只用两维特征表示。
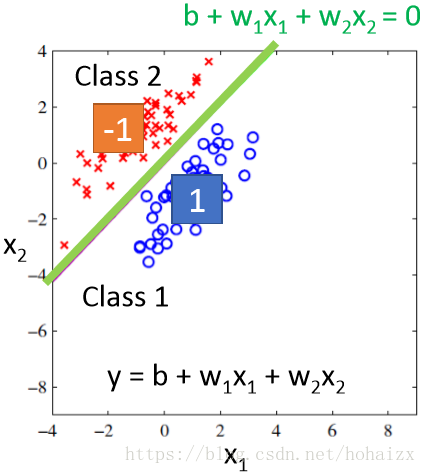
上图中,蓝色的点目标值是1,代表类别1;红色的点目标值是-1,代表类别2。现在需要找到一个函数对这些点进行拟合,如图中绿线所代表的函数b+w1x1+w2x2=0。对于一个样本点,如果其对应的函数值大于0,则认为其属于类别1,反之属于类别2。这么做看起来好像也是可以的,但现在我们考虑另外一种情况,如下图所示
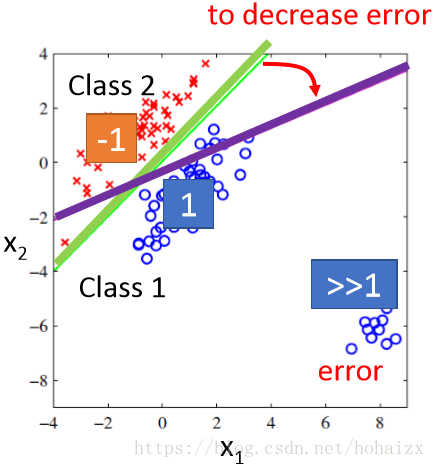
此时,在类别1中加入了右下角这些点,如果仍然采用绿色那条线所代表的函数进行预测,这些新加入进来的点的误差将特别的大,为了缓解由此带来的误差,绿色的线将往右下角偏移,以此减少误差。但这么做明显是不符合常理的,误差虽然减少了,但也带来了更严重的分类类别错误问题。造成这个问题的本质是损失函数定义的不恰当,回归问题种将损失函数定位为误差函数是因为回归的目标是尽可能拟合样本点,但分类问题的目标是尽可能将样本点分类到正确的类别中,仍然使用误差函数作为损失函数显然是不合适的。会闹出这样的笑话:对于那些类别明显的点,回归问题求解的惩罚反而更加严重。另外对于多分类问题种,我们给每个类别指定一个对应的目标值,在机器看来这些目标值之间是有联系的,比如:类别1目标值指定为1,类别2目标值指定为2,类别3目标值指定为3……计算机在寻找样本之间的关系时,会默认类别2和类别3要比类别1和类别3更加有关联,因为3和2更加靠近。
分类问题
分类问题的求解过程同样可以分为三个步骤:
1、确定一个模型f(x),输入样本数据x,输出其类别;
2、定义损失函数L(f),一个最简单的想法是计数分类错误的次数,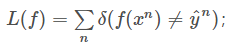
3、找出使损失函数最小的那个最优函数。
上面的做法中,我们寻找到的最优函数直接计算出了p(c|x),即给出了样本x属于每个类别cc的概率,这是一种解法。我们将其称作判别式(discrimination)方法,因为我们直接对样本所属类别进行了判断,相应的模型称作判别式模型。这一篇博客我们换一个角度思考,从另一个方向解决分类问题。下面以最简单的二分类为例,样本可以根据其类别标签被自然分为两类,那为什么我们不分别对每一类进行研究呢?是否可以发现每一类样本的特性呢?结合我们的研究目标:建模p(c|x),借助概率论条件概率的知识,我们对其进行下转换:
高斯分布
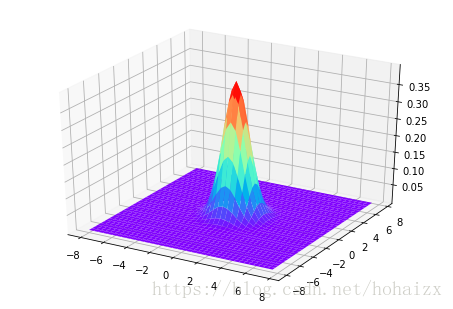
通常我们假定类条件概率p(x|c)符合某种确定的概率分布,训练样本都是从这个分布中随机采样得到的,“未被采样到的点”也对应有一个发生概率。某种确定的概率分布通常被假设为高斯分布(Gaussian Distribution),现在我们需要做的就是根据训练样本确定高斯分布的参数。多元高斯分布的概率密度函数如下: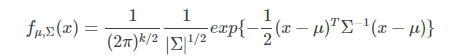
其中k是x的维数,μ是均值向量,Σ是协方差矩阵,μ决定了分布的最高点,Σ决定了分布的形状,二维高斯分布概率密度函数如下:
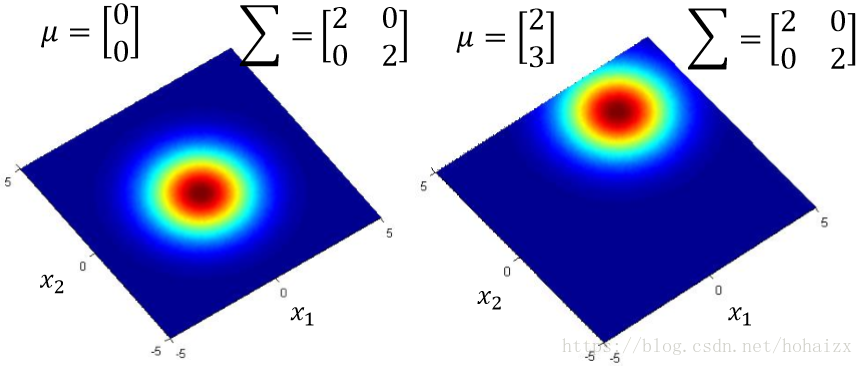
下面两幅图分别展示了μ不同,Σ相同,和μ相同,Σ不同的分布对比
极大似然估计

朴素贝叶斯分类器
上面的计算中,我们将大部分的精力都放在了求解类条件概率p(x|c)上,因为p(x|c)是关于所有属性的联合概率,难以从样本中直接估计得到。一个大胆的假设是认为描述样本的所有属性是相互独立的,因此p(x|c)可以拆解成
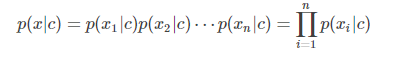
其中,n是属性数目,xi是第i个属性。同样可以假设每一维属性上的概率分布仍然服从高斯分布,此时的高斯分布是一个一维高斯分布,Σ对应一个实值,组成协方差矩阵也只在对角线位置有值,进一步减少了参数数目,得到了更简单的模型。这样的模型被称作朴素贝叶斯分类器(naive Bayes classifier,NB)。
最后,对于样本分布不一定要选择高斯分布,例如如果是二值分布,我们可以假设符合伯努利分布,具体应用中要根据样本特点具体而定,但显示生活中确实有很多分布符合高斯分布。
总结
这一篇博客中,我们从另一个角度介绍了求解分类问题的一类新模型,与判别式模型直接建模p(c|x)不同,这类模型首先对每一类别样本求解p(c)和p(x|c),然后再计算p(c|x),我们将这一类模型称作生成式模型(generative models)。因为求解出p(c)和p(x|c)后,我们也就求出了联合概率p(x,c),也就求出了p(x)=p(x,c1)+p(x,c2)+⋯,有了p(x)我们就能采样生成每一个样本x,所以被称为生成式模型。
参考文献
李宏毅机器学习2017秋http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html