1.监督学习
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。也就是说,在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。
监督学习分类:回归,分类
1.1,回归
下图为一个房价数据集,横轴为面积,纵轴为价格。
通过右图可看出,直线拟合面积750为150,而曲线拟合为200。
因此,回归就是根据训练数据(标出的点)拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。 且输出值为连续值
监督学习意指给一个算法一个数据集,在这个数据集中正确的答案已经存在了(supervised learning refers to the fact that we gave the algorithm a data set in which the "right answers" were given.)。比如给定房价数据集,对于里面的每一个例子,算法都知道正确的房价,即这个房子实际卖出的价格,算法的结果就是计算出更多的正确的价格1.2.分类
另一个监督学习的例子,根据医学记录来预测胸部肿瘤的恶性良性。现在有一个数据集,可以表示为下图所示,横轴表示肿瘤的大小,纵轴表示肿瘤的恶性(1)、良性(0)。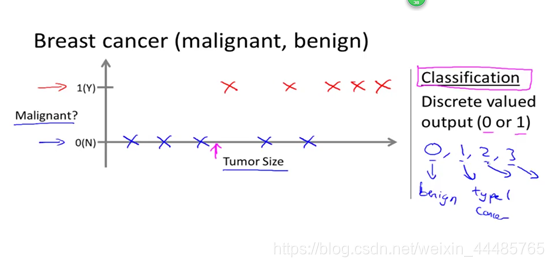
这个时候,机器学习的任务就是估计该肿瘤的性质,是恶性的还是良性的。
那么分类就派上了用场,在这个例子中就是向模型输入人的各种数据的训练样本(这里是肿瘤的尺寸,当然现实生活里会用更多的数据,如年龄等),产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。
所以简单来说分类就是,要通过分析输入的特征向量,对于一个新的向量得到其标签。
2.无监督学习
定义:我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系,可以这么说,比起监督学习,无监督学习更像是自学,让机器学会自己做事情,是没有标签(label)的。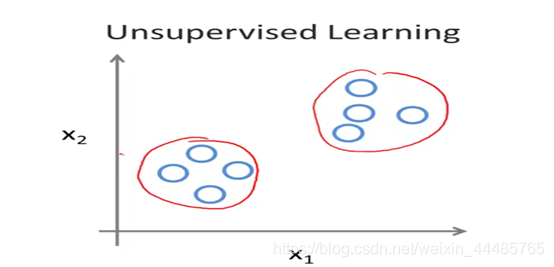
3.总结
有监督学习方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。而非监督学习没有训练集,只有一组数据,在该组数据集内寻找规律。
有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
非监督学习方法在寻找数据集中的规律性,这种规律性并不一定要达到划分数据集的目的,也就是说不一定要“分类”。
这一点是比有监督学习方法的用途要广。 譬如分析一堆数据的主分量,或分析数据集有什么特点都可以归于非监督学习方法的范畴。用非监督学习方法分析数据集的主分量与用K-L变换计算数据集的主分量又有区别。后者从方法上讲不是学习方法。因此用K-L变换找主分量不属于无监督学习方法,即方法上不是。而通过学习逐渐找到规律性这体现了学习方法这一点。在人工神经元网络中寻找主分量的方法属于无监督学习方法。
4.半监督学习
定义:半监督学习(Semi-Supervised Learning,SSL)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。
半监督分类
半监督分类(Semi-Supervised Classification):是在无类标签的样例的帮助下训练有类标签的样本,获得比只用有类标签的样本训练得到的分类器性能更优的分类器,弥补有类标签的样本不足的缺陷,其中类标签 取有限离散值 。
半监督回归
半监督回归(Semi-Supervised Regression):在无输出的输入的帮助下训练有输出的输入,获得比只用有输出的输入训练得到的回归器性能更好的回归器,其中输出 取连续值 ;
半监督聚类
半监督聚类(Semi-Supervised Clustering):在有类标签的样本的信息帮助下获得比只用无类标签的样例得到的结果更好的簇,提高聚类方法的精度;
半监督降维
半监督降维(Semi-Supervised Dimensionality Reduction):在有类标签的样本的信息帮助下找到高维输入数据的低维结构,同时保持原始高维数据和成对约束(Pair-Wise Constraints)的结构不变,即在高维空间中满足正约束(Must-Link Constraints)的样例在低维空间中相距很近,在高维空间中满足负约束(Cannot-Link Constraints)的样例在低维空间中距离很远。