一.摘要
过去几年,在权威数据集PASCAL上,物体检测的效果已经达到一个稳定水平。效果最好的方法是融合了多种图像低维特征和高维上下文环境的复杂结合系统。在这篇论文里,我们提出了一种简单并且可扩展的检测算法,可以将mAP在VOC2012最好结果的基础上提高30%以上——达到了53.3%。我们的方法结合了两个关键的因素: (1)将大型卷积神经网络(CNNs)应用于自下而上的候选区域以定位和分割物体。 (2)当带标签的训练数据不足时,先针对辅助任务进行有监督预训练,再进行特定任务的调优,就可以产生明显的性能提升。
因为我们结合了CNNs和候选区域,该方法被称为R-CNN:Regions with CNN features。我们也把R-CNN效果跟OverFeat比较了下(OverFeat是最近提出的在与我们相似的CNN特征下采用滑动窗口进行目标检测的一种方法),结果发现RCNN在200类ILSVRC2013检测数据集上的性能明显优于OVerFeat。
二,Region proposals 和Alexnet
2.1.Region proposals
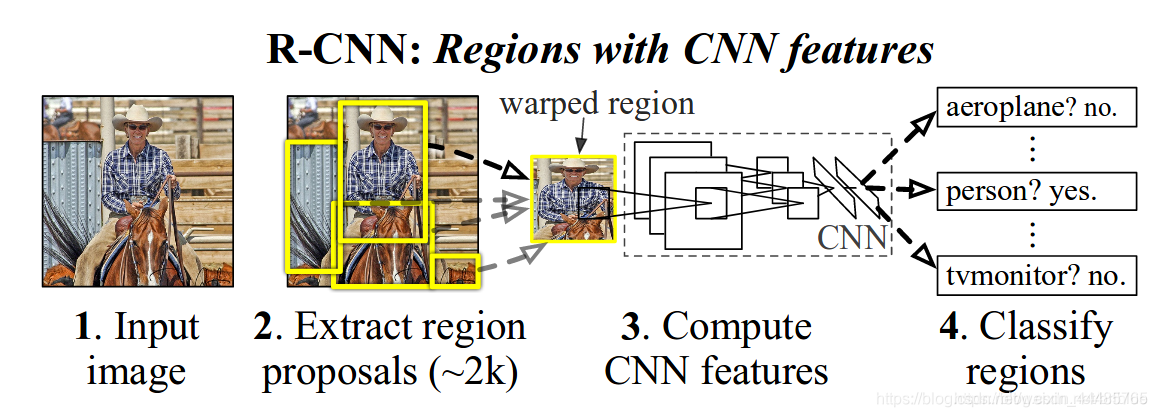
RCNN结合了Region proposals和CNNs,因此起名为R-CNN:Regions with CNN features。所以先来了解一下Region proposals。
上图中每一个黄色的框框住的内容都是一个 region propoal 。
region propoal 通常是使用一种叫 selective search 的方法来确定的。selective search 可以简单的理解为对图片中的每一个像素进行聚类:相邻的相同颜色的像素是一个类别,相邻的相同纹理的像素是一个类别。一个又一个的像素点聚集起来之后就是就变成了上图中一个又一个的块状斑。每一个块状斑就极有可能是我们需要检测的目标。
2.2.Alexnet
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。 这对于传统的机器学习分类算法而言,已经相当的出色。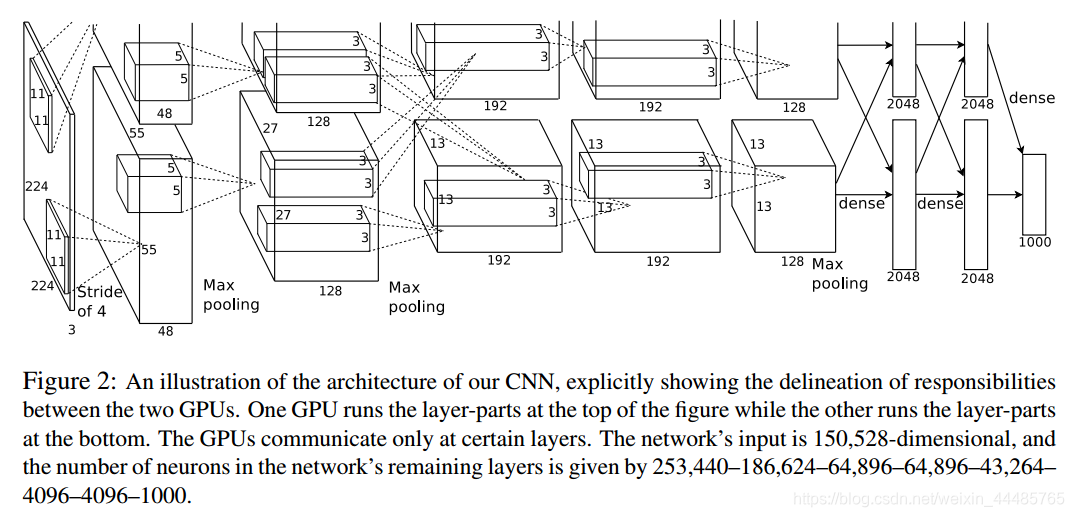
这幅图分为上下两个部分的网络,论文中提到这两部分网络是分别对应两个GPU,只有到了特定的网络层后才需要两块GPU进行交互,这种设置完全是利用两块GPU来提高运算的效率,其实在网络结构上差异不是很大。为了更方便的理解,我们假设现在只有一块GPU或者我们用CPU进行运算,我们从这个稍微简化点的方向区分析这个网络结构。网络总共的层数为8层,5层卷积,3层全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布网络包含8个带权重的层。输入大小:277*277
R-CNN 抽取了一个 4096 维的特征向量,采用的是 Alexnet,基于 Caffe 进行代码开发。为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227*227 的尺寸。
有一个细节,在对 Region 进行变换的时候,首先对这些区域进行膨胀处理,在其 box 周围附加了 p 个像素,也就是人为添加了边框,在这里 p=16。
三,物体检测系统
RCNN的物体检测系统有三个模块构成。
原文:第一个产生类别无关的推荐区域。这些推荐定义了一个候选检测区域的集合;第二个是一个大型卷积神经网络,用于从每个区域抽取特定大小的特征向量;第三个是一个指定类别的线性SVM。
本部分,将展示每个毛块的设计,并介绍他们的测试阶段的用法,以及参数是如何学习的细节,最后给出在PASCALVOC 2010-12和ILSVRC2013上的检测结果。
也就是:
- 生产类别独立的候选区域(Region propals~2k),这些候选区域其中包含了 R-CNN 最终定位的结果。
- CNN卷积神经网络去针对每个候选区域提取固定长度的特征向量。
- 一系列的 SVM 分类器